|
I earned my Ph.D. from the Multimedia Lab at the Shenzhen Institutes of Advanced Technology (SIAT), Chinese Academy of Sciences, in June 2025, advised by Prof. Shifeng Chen and Prof. Chao Dong. I also work closely with Prof. Jianzhuang Liu, who has continuously mentored my research. Prior to that, I received my B.Eng. degree from Sun Yat-sen University in June 2020. During my doctoral studies, I mainly focused on diffusion models for image/video generation, editing, and restoration tasks. I am currently researching efficient vision-language models. Welcome to contact me by email if you are interested in my work or potential collaborations, including internship opportunities. |

|
|
|
|
* indicates equal contribution, # indicates corresponding author |
|
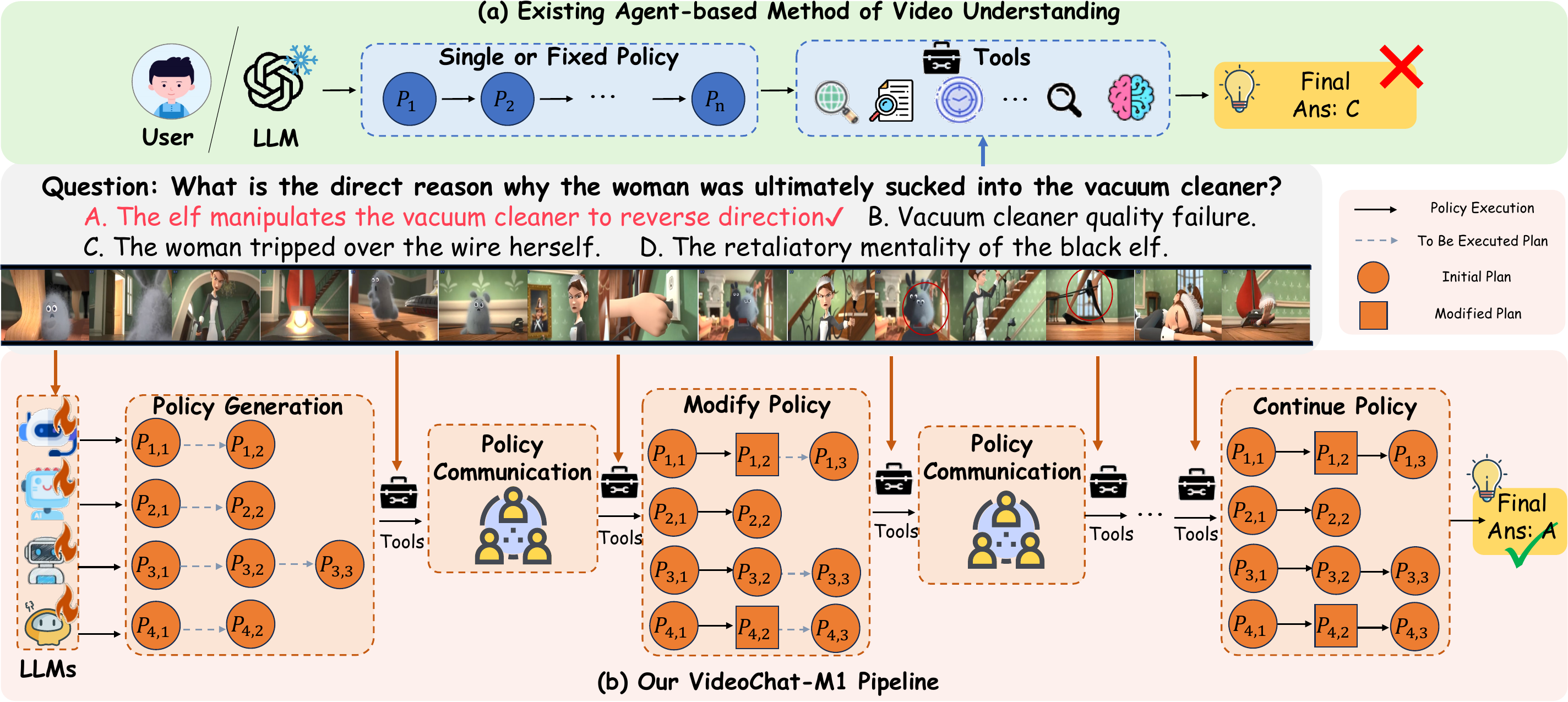
Boyu Chen, Zikang Wang, Zhengrong Yue, Kainan Yan, Chenyun Yu, Yi Huang#, Zijun Liu, Yafei Wen, Xiaoxin Chen, Yang Liu, Peng Li, Yali Wang IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026 [Paper] [arXiv] We propose VideoChat-M1, a multi-agent video understanding framework built around collaborative policy planning. Multiple policy agents learn to generate, execute, and iteratively refine tool-use strategies through reinforcement learning, enabling stronger perception and reasoning on temporally and spatially complex videos across diverse benchmarks. |

|
Yi Huang, Wei Xiong, He Zhang, Chaoqi Chen, Jianzhuang Liu, Mingfu Yan, Shifeng Chen IEEE/CVF International Conference on Computer Vision (ICCV), 2025 [Paper] [Project] [arXiv] We propose DINO-guided Video Editing (DIVE) for subject-driven video editing conditioned on text prompts or reference images. By leveraging semantic features from a pretrained DINOv2 model, our framework simultaneously aligns motion trajectories for temporal consistency and learns targeted LoRAs to precisely preserve the subject's identity. |

|
Yi Huang, Jiancheng Huang, Yifan Liu, Mingfu Yan, Jiaxi Lv, Jianzhuang Liu, Wei Xiong, He Zhang, Liangliang Cao, Shifeng Chen IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025 ESI highly cited [Paper] [Project] [arXiv] We present a comprehensive survey of diffusion models for image editing, analyzing existing methods across various learning strategies, user-input conditions, and specific tasks. To further evaluate text-guided editing algorithms, we propose EditEval, a systematic benchmark featuring an innovative LMM Score metric. |
|
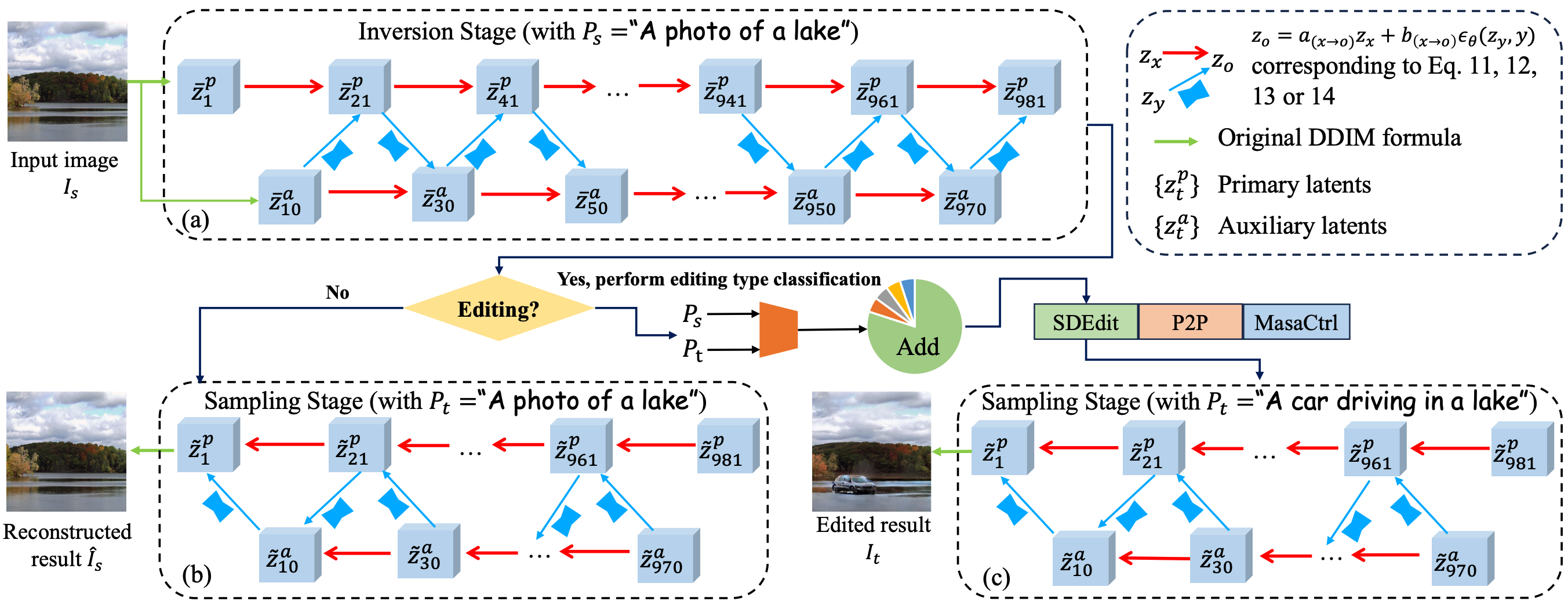
Jiancheng Huang*, Yi Huang*, Jianzhuang Liu, Donghao Zhou, Yifan Liu, Shifeng Chen IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), oral, 2025 [Paper] [arXiv] We propose Dual-Schedule Inversion to address reconstruction failures common in DDIM Inversion for text-conditional image editing. By mathematically guaranteeing reversibility without fine-tuning, our method adaptively combines with various editing techniques to seamlessly modify targeted semantics while preserving the original identity of unedited regions. |
|
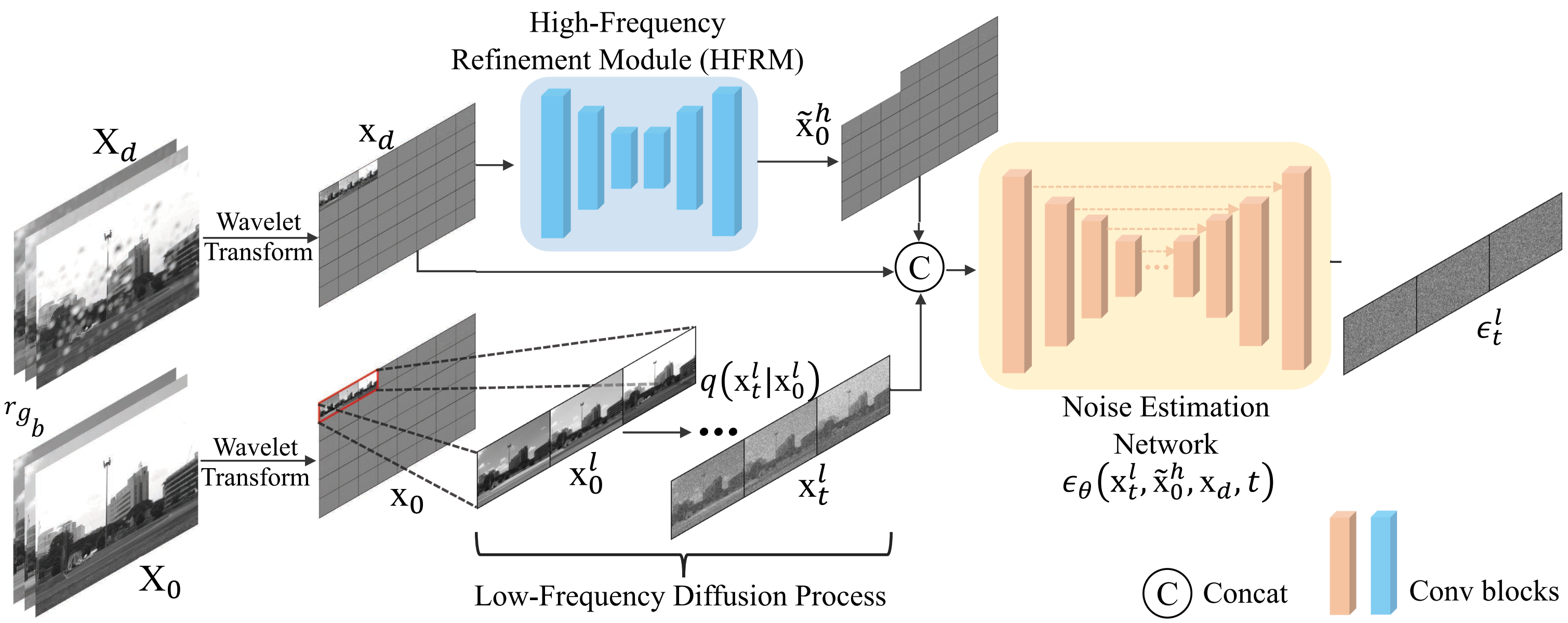
Yi Huang, Jiancheng Huang, Jianzhuang Liu, Mingfu Yan, Yu Dong, Jiaxi Lv, Chaoqi Chen, Shifeng Chen IEEE Transactions on Multimedia (TMM), 2024 ESI highly cited [Paper] [Project] [arXiv] We propose a Wavelet-Based Diffusion Model (WaveDM) to address the slow inference times of diffusion-based image restoration. By learning clean image distributions in the wavelet domain with an Efficient Conditional Sampling (ECS) strategy, our approach achieves state-of-the-art performance across multiple tasks while being over 100x faster than vanilla diffusion models. |

|
Jiaxi Lv*, Yi Huang*, Mingfu Yan, Jiancheng Huang, Jianzhuang Liu, Yifan Liu, Yafei Wen, Xiaoxin Chen, Shifeng Chen IEEE/CVF Conference on Computer Vision and Pattern Recognition PBDL Workshop (CVPRW), Best Paper Runner-Up, 2024 [Paper] [Project] [arXiv] We propose GPT4Motion, a training-free framework that leverages large language models and physics engines to address computational costs and motion coherency issues in text-to-video generation. By using GPT-4 to generate Blender scripts for physical simulation and integrating these components with Stable Diffusion, our method efficiently produces high-quality videos with consistent and physically accurate motions. |
|
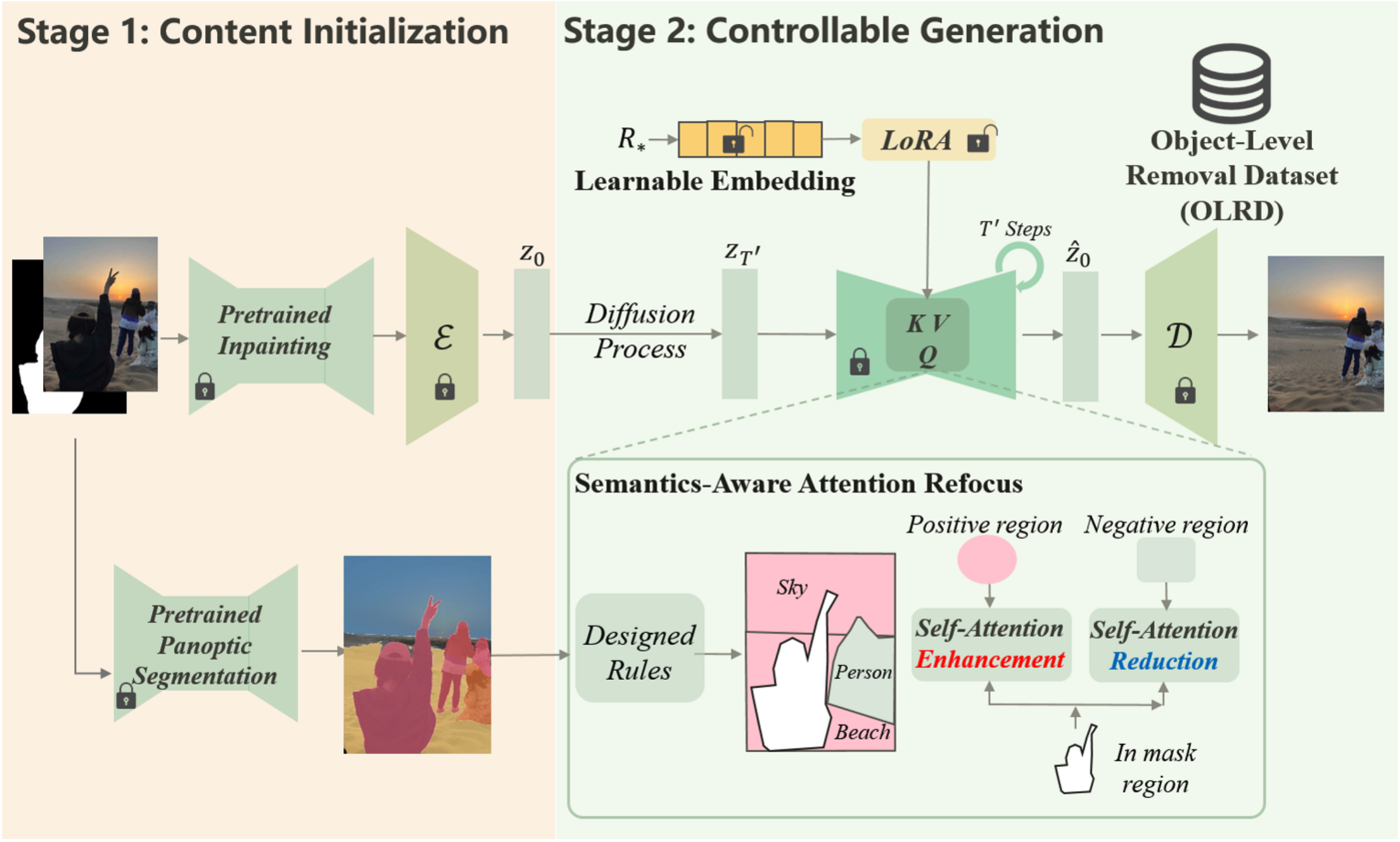
Fan Li, Zixiao Zhang, Yi Huang, Jianzhuang Liu, Renjing Pei, Bin Shao, Songcen Xu European Conference on Computer Vision (ECCV), 2024 [Paper] [arXiv] We propose MagicEraser, a tailored diffusion-based framework for object erasure that addresses the incongruent generation and prompt-dependency issues of existing inpainting methods. By integrating prompt tuning and semantics-aware attention refocus modules within a two-phase generation process, alongside a novel data construction strategy, our approach achieves fine-grained control and effectively mitigates undesired artifacts. |

|
Yi Huang, Yu Dong, He Zhang, Jiancheng Huang, Shifeng Chen IEEE Transactions on Consumer Electronics (TCE), 2023 [Paper] We propose a novel, memory-efficient approach to high-resolution image harmonization by utilizing image-adaptive lookup tables (LUTs) instead of resource-heavy full image reconstruction. By employing a deep model to fuse basic LUTs for global color transformation alongside a spatial attention module for local refinement, our method achieves competitive performance with a significantly smaller model footprint. |
|
|
|
|
© Yi Huang | Last updated: March, 2026